废话
Selenium,Python的浏览器自动化大佬库,称霸Python浏览器自动化领域。
注意,阅读本文需要有亿点点前端知识才容易理解。要是大佬看到了不会冒犯到吧,不会吧……
安装 Selenium 包
Pip 安装
1 | |
源码包安装
1 | |
安装 对应浏览器的 WebDriver
Edge: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Chrome (淘宝源) : https://npm.taobao.org/mirrors/chromedriver/
Firefox: https://github.com/mozilla/geckodriver/releases/
IE: http://selenium-release.storage.googleapis.com/index.html?
Edge:对应浏览器对应版本,对应下载。
Chrome: 注意,先在设置 –> 关于Chrome 里查看Chrome版本号,再去我给的淘宝源里找。再注意,在淘宝源里找版本时,如果没有本浏览器的版本的话,就找自己版本号的上一个。
Firefox: 选择自己系统版本下载对应的。我不用火狐,报错别怪我 (弱小.jpeg)
IE: 这我没啥注释,但建议IE11用用2.5版本就好。(这年头还有人用IE?可怕可怕。)
下载解压后把文件放在Python目录下的Scripts目录中,别问为啥,问就是懒得加环境变量。Linux的可以放在/usr/bin下。
开始!
废话忒多了,进入正题。
基础
咱为啥要用Selenium,就是可以爬到普通爬虫爬不到的东东,用Selenium,更方便、更快捷、更显逼格!(打广告)
1 | |
大概会看到这样: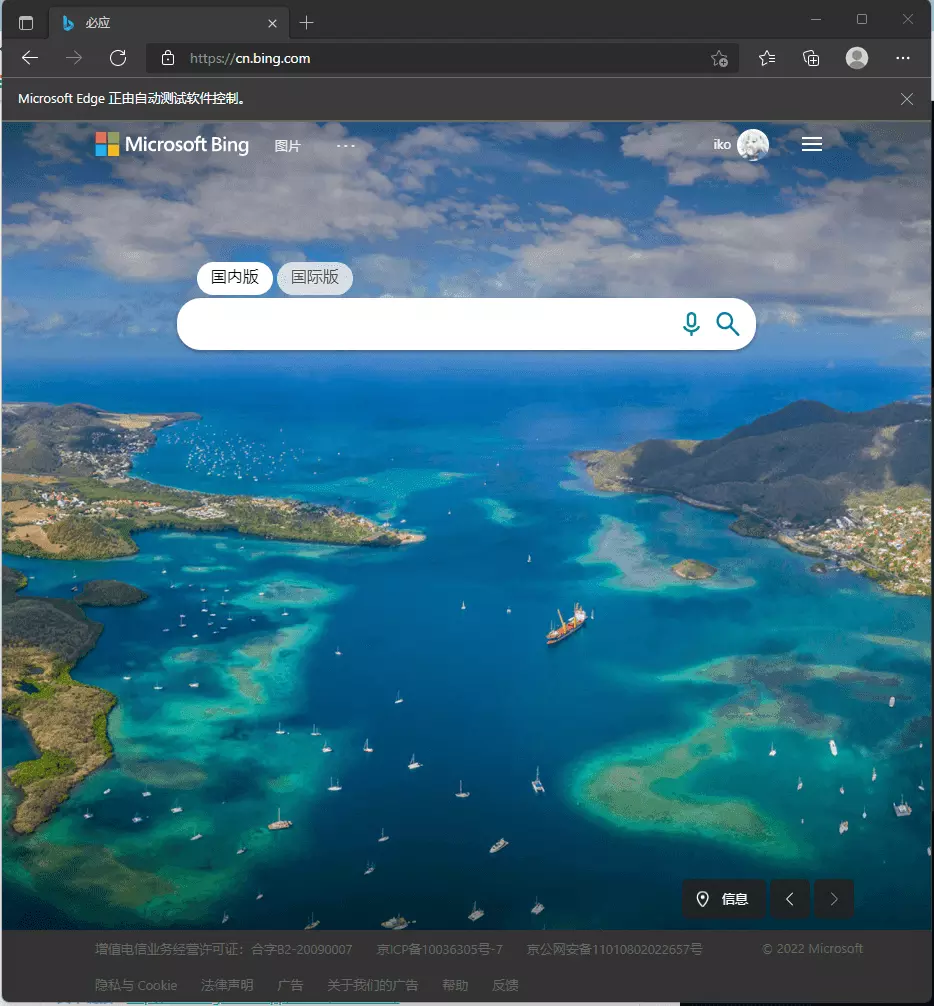
如何往输入框内填入文字并点击搜索按钮进行搜索?
Very Easy.
不要动你那个界面,打开DevTools,找到搜索框的元素,[右键]{.kbd} - [Copy]{.kbd} - [CopyXpath]{.kbd},再回到代码这。
1 | |
注意,find_element_by_xpath这个函数很微妙,它的工作是在整个页面找一个元素,敲黑板,是一个。还有一个函数是find_elements_by_xpath,找的是一堆元素。很多手残的会多敲个s,找了半天的bug。说的就是我😭
:::
运行。
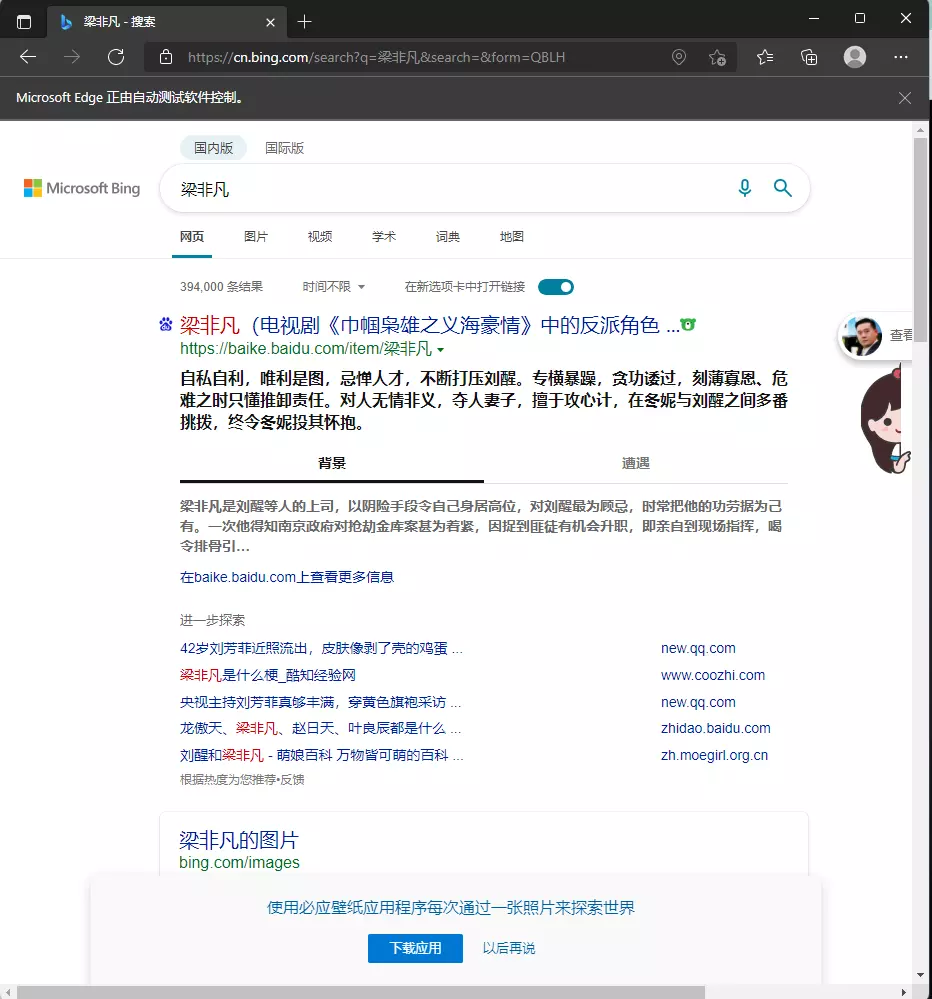
可以看到,输入框里输入了梁非凡,接着干。
按照上次那样,打开Devtools,找到搜索按钮的元素,接着Copy –> Copy Xpath。
1 | |
运行。
搞定!
还有一种方法,将click()换成submit(),或是Webdriver模拟用户点击按键[Enter]{.kbd}进行搜索。进阶会讲。
进阶
学了总要运用,搞个爬虫实例。
实战:
(鸽着先,坑以后再填~)